流式处理常用概念
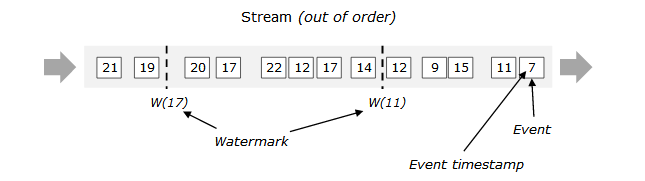
1、watermark 水印:用于推进窗口处理中的钟的时间,指明当前已处于处理哪一部分数据的时间;一般生成于Source,也可以生成于Source之后;水印对于乱序数据,设置的时间一般都与它本身的时间无关,这样即使无法通过事件时间判断数据是否已全送达到窗口,水印也可以告诉窗口处理之前的一批数据已经全部到达窗口。
PS: 乱序数据如何处理迟到的数据,一般都是设置等待一定数量的迟到数据。
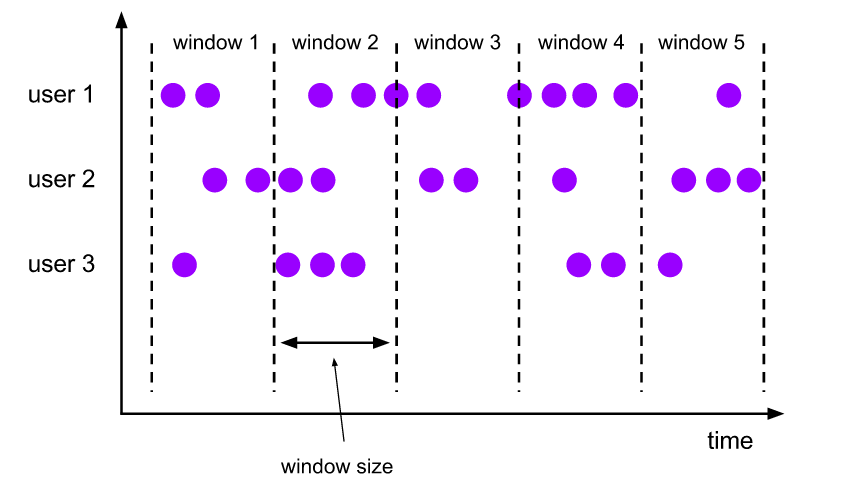
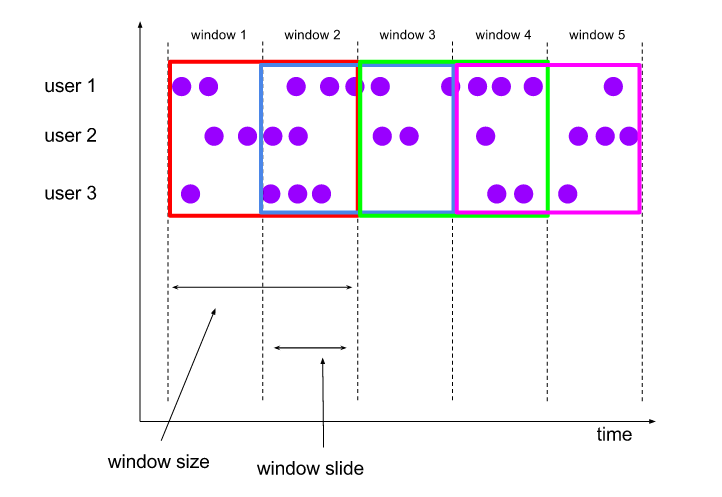
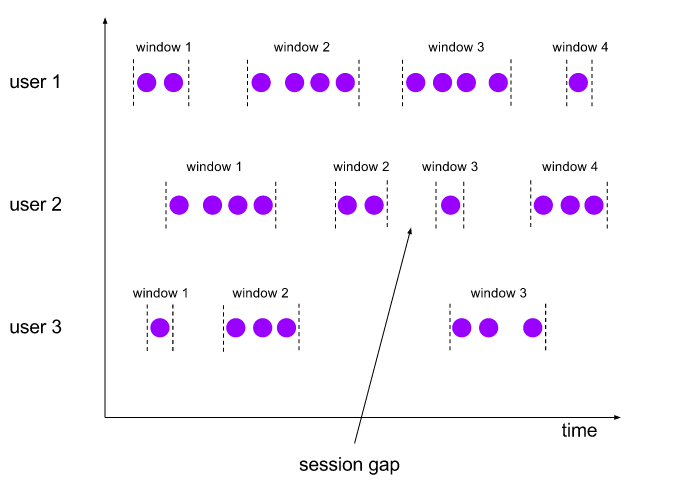
2、window 窗口:支持多种窗口,包括滚动窗口、滑动窗口、会话窗口、全局窗口;针对分组数据与未分组数据,支持窗口行为,前者以key分离并发,后者单一并发;支持不同数据处理场景的需求;
PS:比如统计五分钟时间段中的点击数;或者统计每隔1分钟,十分钟时间段的点击数;或者某一用户,在所有间隔不大于1分钟内的所有点击数;或者在某一页面下,当点击到某一标题文章时,之前已有的所有点击数。

(1)为第一个属于窗口的元素创建窗口
(2)窗口由触发器与处理函数组成,trigger的条件决定何时调用function;窗口还有evitor,一般作用于触发器和处理函数前后,用于清理元素。
(3)当水印达到窗口的创建时间加延迟时间时,会清理窗口的元素
3、Event Time : 支持的时间场景,包括ProcessTime 处理时间、IngestionTime 提取时间、EventTime 事件时间;数据带有的时间戳分别是处理时赋值、数据进入flink时赋值、数据生成时赋值;
(1)source中可指定window assigner,继承的WindowAssigner是基于时间分配元素到窗口的
5、operator 操作:与输入输出绑定,或者应用一个或多个输入产生结果。
针对streaming与batch有不同的操作父类:
streaming的operator将在process里直接调用
batch的operator将由translation从api转换到core的operator
6、function 函数:用户定义的内容

并发情况下的架构
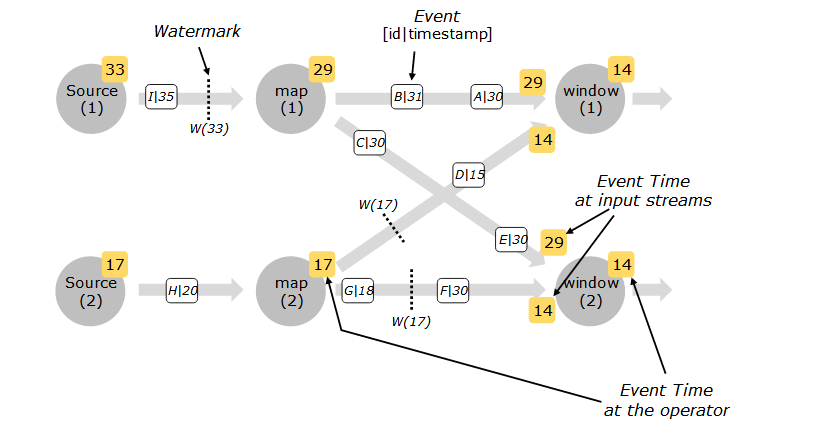
窗口与事件时间的概念
水印注入:TimestampsAndPeriodicWatermarksOperator和TimestampsAndPunctuatedWatermarksOperator这两个算子往事件流注入水印
(1)周期水印:
(2)间断水印:
(3)已实现水印示例:
1.升序时间戳 AscendingTimestampExtractor:时间戳只是在每个并发的source Task里升序;水印归并机制会自动在shuffle、unoin、connect或merge时生成正确的水印
2.允许混合一定量的迟到数据 BoundedOutOfOrdernessTimestampExtractor:产用户可预见迟到区间的数据。其参数maxOutOfOrderness,是在为给定窗口计算最终结果时,在要被忽略之前,数据可被允许迟到的最大时间。
水印与窗口的关系
水印的时间决定了什么数据会被处理,主要作用于处理乱序、迟到的数据
窗口的时间决定了什么时候对窗口内的一批数据进行处理。窗口的消亡取决于window End-Time
stream connector:连接器
(1)Hdfs : Bucketsink,输出目录/path/{date-time}/part-{paraller}-{attempt},当文件大小达到bucket上限将roll,新创建一个文件。当第一个数据到达以后,已当前时间戳作为{date-time}创建目录。
(2)Kafka:source、sink
(3)Canssandra: sink
(4)ES:sink
(5)RabbitMQ:source、sink
(6)NiFi:source、sink
(7)external:AcrtiveMQ(source、sink)、Flume(sink)、Redis(sink)、Akka(sink)、Netty(source)
process function 低级别操作
可以实现ProcessFunction来完成功能。
可以被认为是一个有着key状态和定时器的FlatMapFunction;
为了容错,提供了RuntimeConetxt中的state,和其他状态function一样的使用方式。
定时器允许应用在process\event time中产生变换。
调用processElement()获取一个context,能访问元素的event-time时间戳。
TimerService能够为event/process time实例注册一个回调函数,当定时器到达,onTimer()将会被调用。其中会包含一个这个定时器创建的,key值范围内的状态集合。定时器可以操作这个状态集合。
也可以使用CoProcessFunction去归并操作两个输入;分别调用ProcessElement1()、ProcessElement2()
侧流输出
其实就是变相的多路输出。
当要使用侧流输出,需要定义一个OutputTag用来识别侧边的输出流。
可以在ProcessFunction内指定Tag输出,也可以使用SingleOutputStreamOperator的getSideOutput()方法获取侧边流,再进行操作或输出。
工作状态
状态可存在于function与operator。他们通过元素或者事件的各自的处理过程,存储数据。能为任意种类的更多合成操作声明临界建立的区块。
flink管理着应用的状态,意味着内存管理允许保存巨大的状态;为了状态支持容错,还需要对它做checkpoint。
以下为几大常用状态实现:
Keyed State:仅应用于KeyedStream的function和operator,可以认为其为被分区、分片的Operator State;每个Key都有精准的状态分区,逻辑关联<parallel-operator-instance,key>的这个唯一组合;每个key都属于keyed操作的并发实例的精确之一,还可以简单认为它是<operator,key>
Keyed State还会被组合成Key groups;它是原子的,所以可以被分发。Key groups的数据精确等于最大并发的数量,当每个并发运行的时候,key Operator可以通过一个或多个Key groups进行工作。
Operator State: 其实是non-keyed state,每一个operator state与一个并发的operator实例关联;当并发数改变时,也支持在并发operator实例之中重新分发状态。
比如使用Kafka,每个并发实例的消费者,都会维持一个topic分区的map与offset到operator state
Raw State(元状态):operator保持在他们自己的数据结构中的状态;当checkpoint后,他们会写一串二进制到checkpoint,flink无法知道状态内容只能看到二进制数据。
Managed State(管理状态):是在runtime阶段被控制的数据结构;比如内部hash表,比如ValueState、ListState。runtime阶段编码states然后将它们写入检查点。
datastream可以使用管理状态,但元状态接口只能在实现了operator时被使用。建议使用使用管理状态,因为当并发数改变时,可以自动重新分发,并且能被更好的进行内存管理。
检查点机制
为了工作状态的容错,需要引入检查点机制。检查点允许恢复流的状态和位置,保证应用等同无失败执行。
要实现检查点机制,需要:
1、一个持久的数据源,能够在一定时间内重放记录。比如持久化的消息队列,或者文件系统。
2、一个持久化的状态存储,经典的比如分布式文件系统。
默认checkpoint是不可用的,可以调用StreamExecutionEnvironment.enableCheckPointing(n),指定检查点的间隔毫秒。
别的检查点配置包括:
1、exactly-once 或者 at-least-once:精确一次适合更多的应用,至少一次适用于极小延迟(几毫秒)的应用。
2、检查点时间:多少时间之后检查点终止
3、两次检查点之间的最小时间:比两个检查点的间隔时间要更易设置,因为常常检查点会花费长于平均时间,比如目标存储系统的延迟。检查点之间的间隔时间决不会小于最小时间。
4、并发检查点的数量:默认系统当一个在进行时,不会触发另一个检查点;这个保证topology不会花费太多时间在检查点;这个允许多个覆盖的检查点,适用于如果有确切延迟的处理,比如请求外部服务,但是还想要比较频繁的检查点去重新处理很少的失败。
5、外部检查点:可以配置周期检查点,持久到外部。会写meta到可持久化的存储,在作业失败以后也不会自动清理。这个可以在你的作业失败后用于继续你的作业。
相关配置:
1、state.backend 状态后端:可以选用直接在JM的内存中存储,也可以选择文件系统。如果选择选择文件系统,需要设置一个JM可访问的fs路径。
2、state.checkpoint.dir:外部检查存储meta的路径
3、state.checkpoint.num-retained:完整检查点保存的个数。如果超过一个,如果最新的检查点失败了,能从早前的检查点进行恢复。
迭代作业需要强制设置才能使用检查点机制:env.enableCheckpointing(interval, force = true).